Unchained Index
Exploring how to deliver Web 3.0 native data without resorting to old-fashioned Web 2.0 based APIs.
Project Description
Blockchain explorers exhibit none of the qualities of blockchains. They do not preserve the immutability of the data they deliver. In fact, they frequently alter or enhance the data so as to capture applications built upon them. Blockchain explorers, like all Web 2.0 websites, invade user's privacy by tracking their behavior (either through logins or by tracking IP addresses). They make no promises in regards to privacy invasion. In fact, their ad-revenue-based business models will necessitate invasive surveillance capitalism. They are also, obviously, not decentralized.
Moreover, the incentives of Web 2.0 websites, such as explorers, are in misalignment with the incentives of their users. We think this is something the distributed web may be able to solve. Websites seek to maximize the number of users while simultaneously minimizing the cost of retaining each user, thereby maximizing their revenue. This is in direct conflict with the incentives of the user, who wants to maximize the utility of the available data while simultaneously minimizing its cost and maximizing its availability.
The Unchained Index project explores aligning the incentives of data providers with their end users, while at the same time enhancing privacy and minimizing centralization. We do this by taking full advantage of the immutability of certain blockchain data in a novel way, introducing a method of providing both raw and derived data that is deterministically reproducible. To accomplish this, we use IPFS, which fits perfectly given its content-addressable nature, and an Ethereum smart contract.
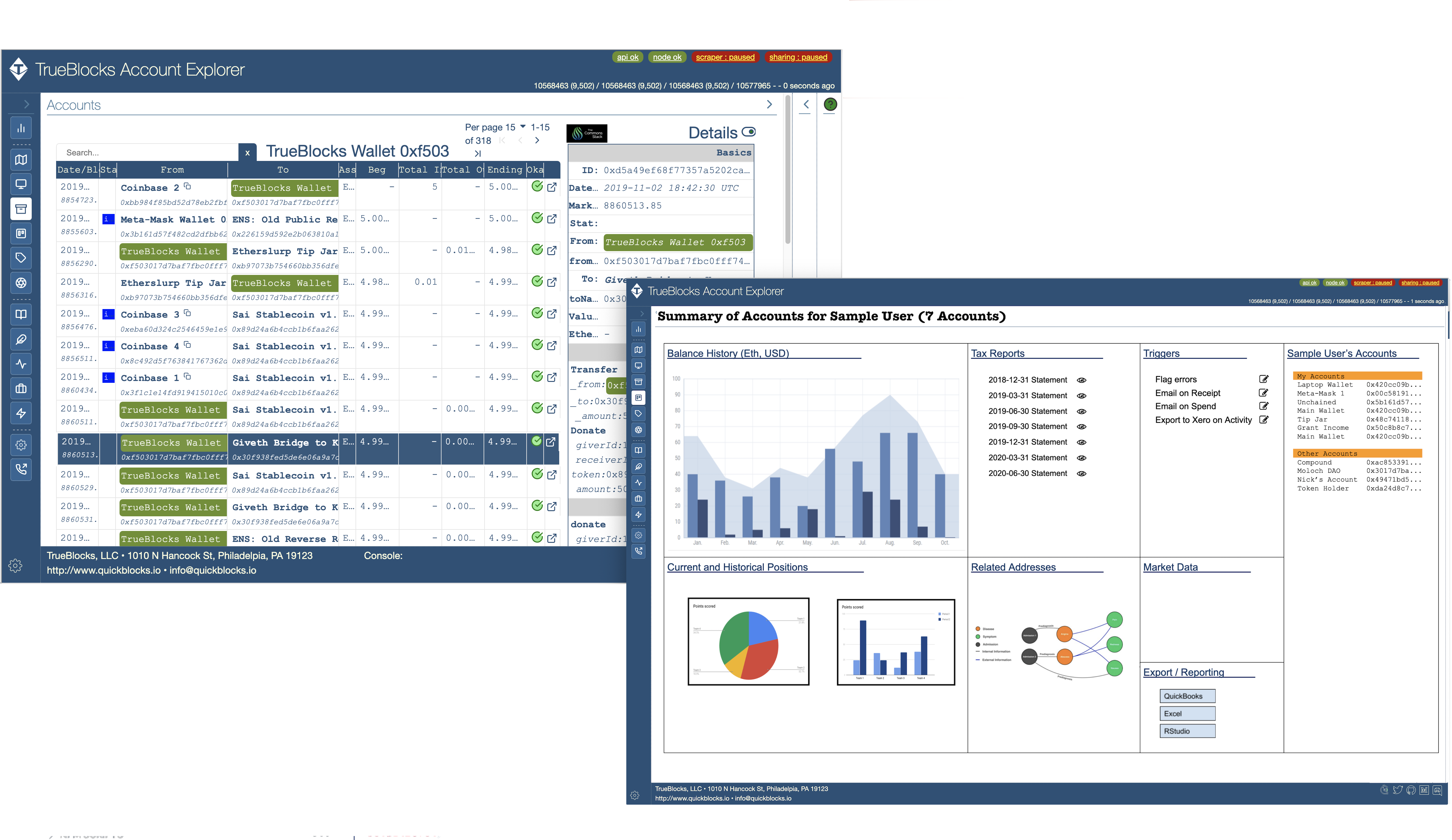
The TrueBlocks application, which we call an Account Explorer, derives an index of every appearance of every address anywhere on the chain. Previously, the software delivered this data via an old-fashioned web 2.0 API and a website, losing all of the benefits of blockchains. (Alternatively, it could deliver the data directly on the user’s machine, however, this required the user to run their own infrastructure including running an Ethereum node.)
Our HackFS hack tries to solve this problem using IPFS. We strive to 'invent' a new method of delivering data while maintaining privacy and the unique features of blockchain data we find so important (immutability, un-capturability, decentralization, and verifiability).
How it's Made
Part of TrueBlocks is a long-running process called blockScrape that 'scans' the blockchain extracting all appearances of any address anywhere on the chain.
After processing each block, blockScrape checks to see if it is time to "consolidate." Each time the number of addresses in the growing list of addresses overtops 1,000,000 records, blockScrape consolidates the data into time-ordered snapshots that we call 'chunks'. It then builds a bloom filter, which is an order-of-magnitude smaller, representing the chunk.
Other processes (our Account Explorer) reads this time-ordered index of appearances to provide accurate summaries and lists of historical transactions for an address to the end user. This process is hundreds of times faster than querying the node directly, but, because TrueBlocks does not extract the entirety of the Ethereum database, as most blockchain explorers do, the application works on a small, local, desktop computer.
If the user is running their own local node (such as a dAppNode, for example), that user can get a fully private, no-third-party interaction with their own data in exact alignment with the decentralized web ethos.
Prior to this hack, we had no way to publish the results of the blockScrape process. Each user had to run their own version of blockScrape against their own local node producing their own derived, chunked index.
The Unchained Index (our project for this hackathon) aims to fix that.
We created three new components. A publisher which runs on a server, a consumer that runs on the end user’s machine, and a smart contract that runs on Ethereum.
The publisher inserts into each snapshotted chunk the git commit of the TrueBlocks code that was used to generate that chunk. Anyone with access to GitHub and their own Ethereum tracing node can reproduce our derived, chunked index. Making the data reproducible in this way makes it impossible for us (or anyone) to capture the data. It also encourages people to audit our work. With a sufficient number of people auditing the work and the reproducible nature of the work, there will be no need to further confirm the data in the future. The entire ecosystem can simply pull the chunked index from IPFS (assuming they know the hashes of where the data resides) and where the data has been preserved (or pinned).
So that everyone is aware of new the chunk, we create a manifest listing all of the currently pinned data. This manifest is pinned as well, and the hash is published to the Unchained Index smart contract, which is purposefully very simple, storing only the most recent manifest hash and generating an event.
The Consumer piece of code watches for the latest manifest hash from the smart contract and downloads new manifests to the end user’s machine. It then downloads any new bloom filters and consults them to see if any relevant index chunk needs to be downloaded. It then pins both the new blooms and any downloaded chunks on the end user’s machine.
In this way, each user is automatically pinning the bloom filters, making subsequent queries for future addresses of interest fast enough to be useful. Each user also downloads and pins those portions of the chunked index that they are interested in. In this way, each user carries the smallest amount of data that allows them to get what they want, which is a record of their own behavior on the chain.
This method also simultaneously shares portions of the data with the community (each chunk contains more than just the user’s appearances). As 'light' users use the system, they download and pin a 'light' portion of the index. As 'heavy' users use the system, they download and pin 'heavier' portions of the index—as they should, given their heavier usage. We believe this naturally distributes the data across the user base in a way that is fair and equitable, while at the same time making the data less prone to capture, more accessible, and faster.

