Fragment
Fragment is a proposition to leverage Filecoin, IPLD schemas and the Fluence network to organize data processing pipeline in open contexts, foster collaboration and data re-usability.
Project Description
Data is almost always more valuable once it is processed than in its raw form. In the field of data science, this fact partly explains the popularity of tools that allow tracking and replication of process pipelines like Jupyter notebooks, and of collaboration and exchange platforms such as Kaggle.
But while these tools are very effective in centralised and private contexts, what about more open contexts? It is well known that Open Data often suffers from problems of inconsistent and muddled data. Is it impossible to effectively organize traceability of data transformation history by relying solely on open and decentralised networks?
Linked Data technologies obviously seem to be the most appropriate tools to meet this challenge, but they are still under-used in schema-free contexts that the flexibility of data science requires.
In this project, we therefore set out to define as simply and flexibly as possible what could be considered as a data transformation pipeline, how this information could be shared over decentralised networks and what would be the most interesting interactions with open computing networks. To demonstrate the power of this model, we have built on top of this framework a demonstration web application that also focuses on collaboration, allowing users to share their data transformation pipelines but also to comment, correct and improve those of others, relying only on fully open networks.
How it's Made
At the core of our project, we find the definition of an IPLD schema tailored for a specific use in conjunction with the Fluence network. Together, we think that they create a powerful and flexible way to run data transformation pipelines and store this information, leveraging only decentralised networks.
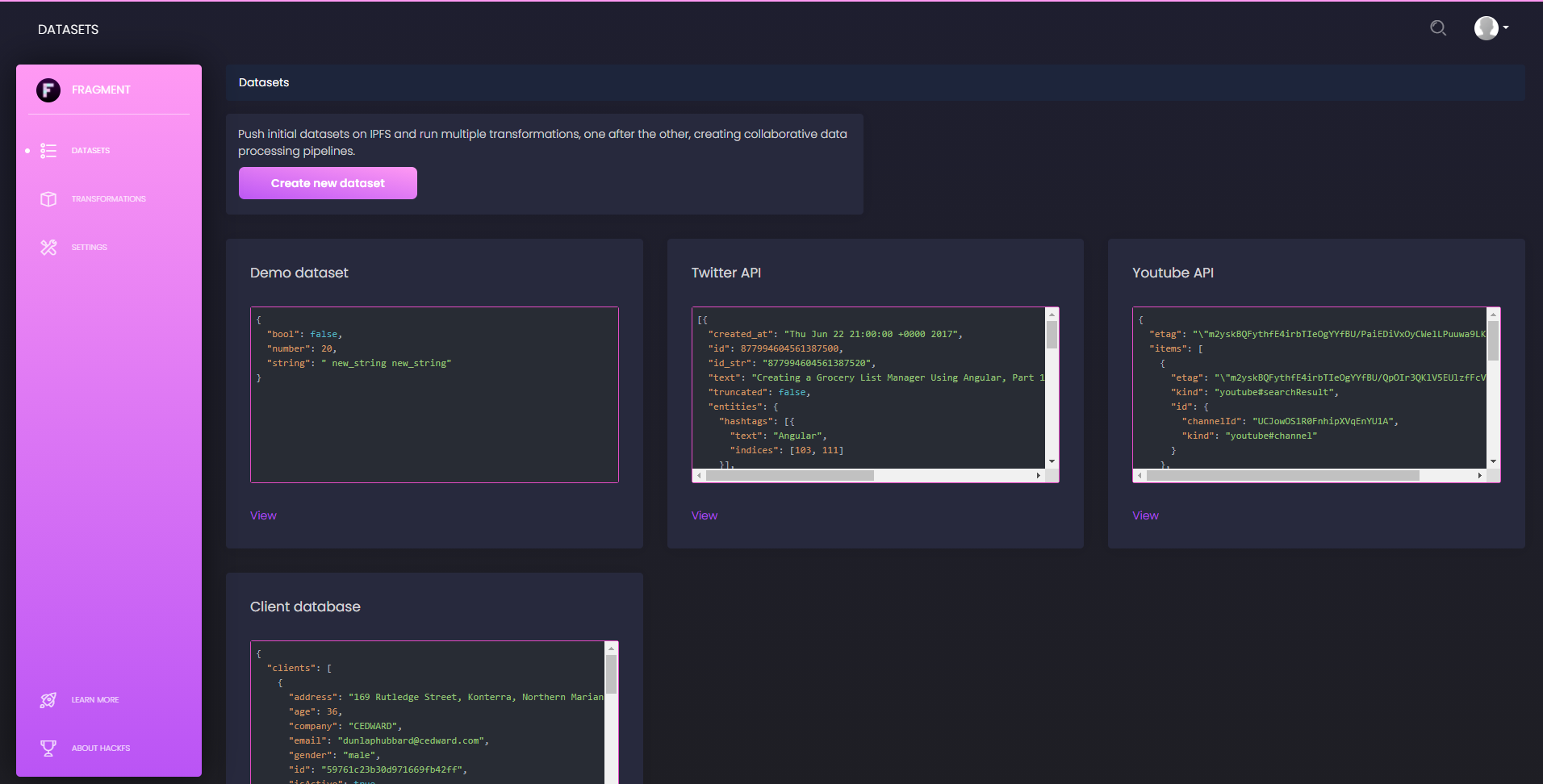
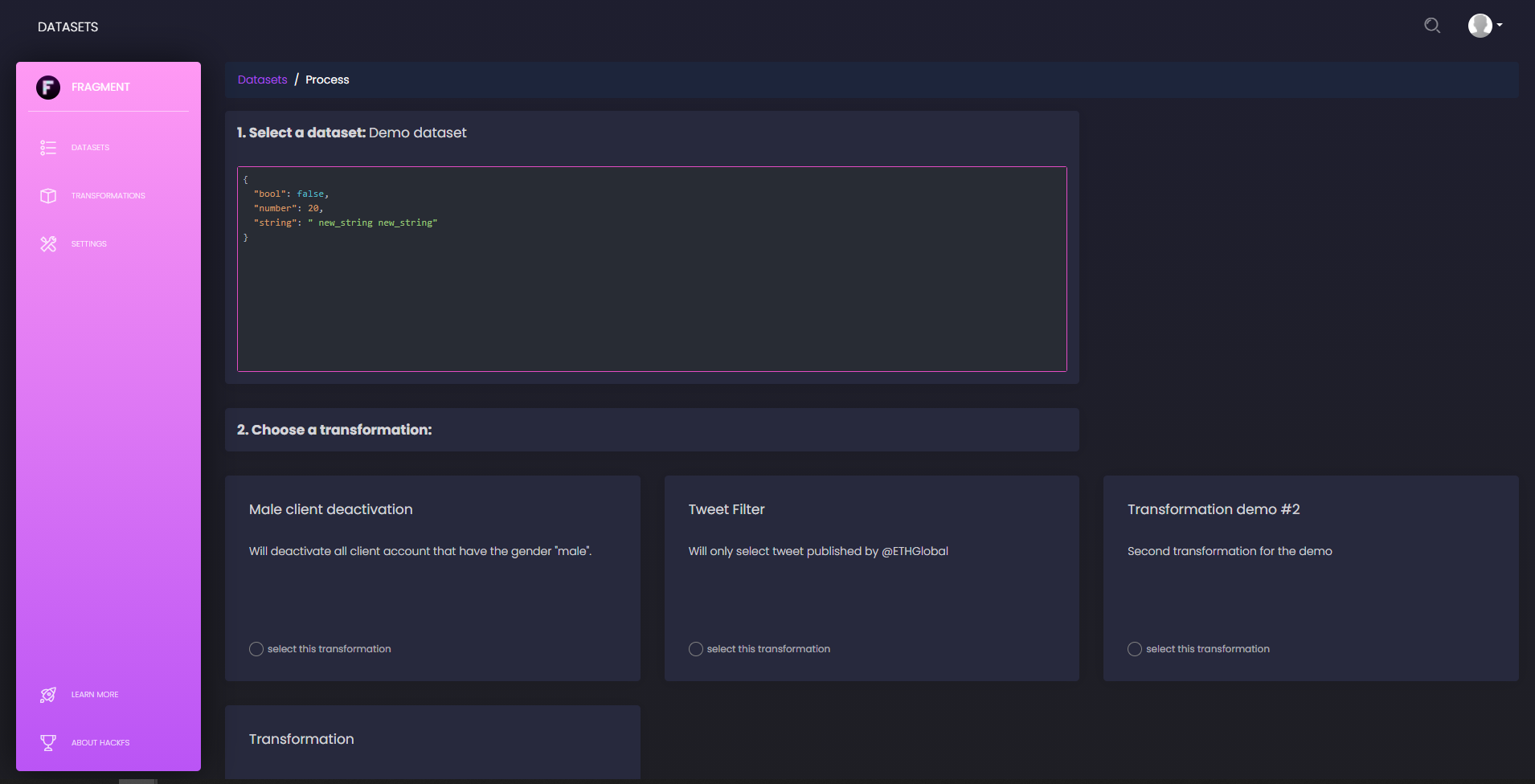
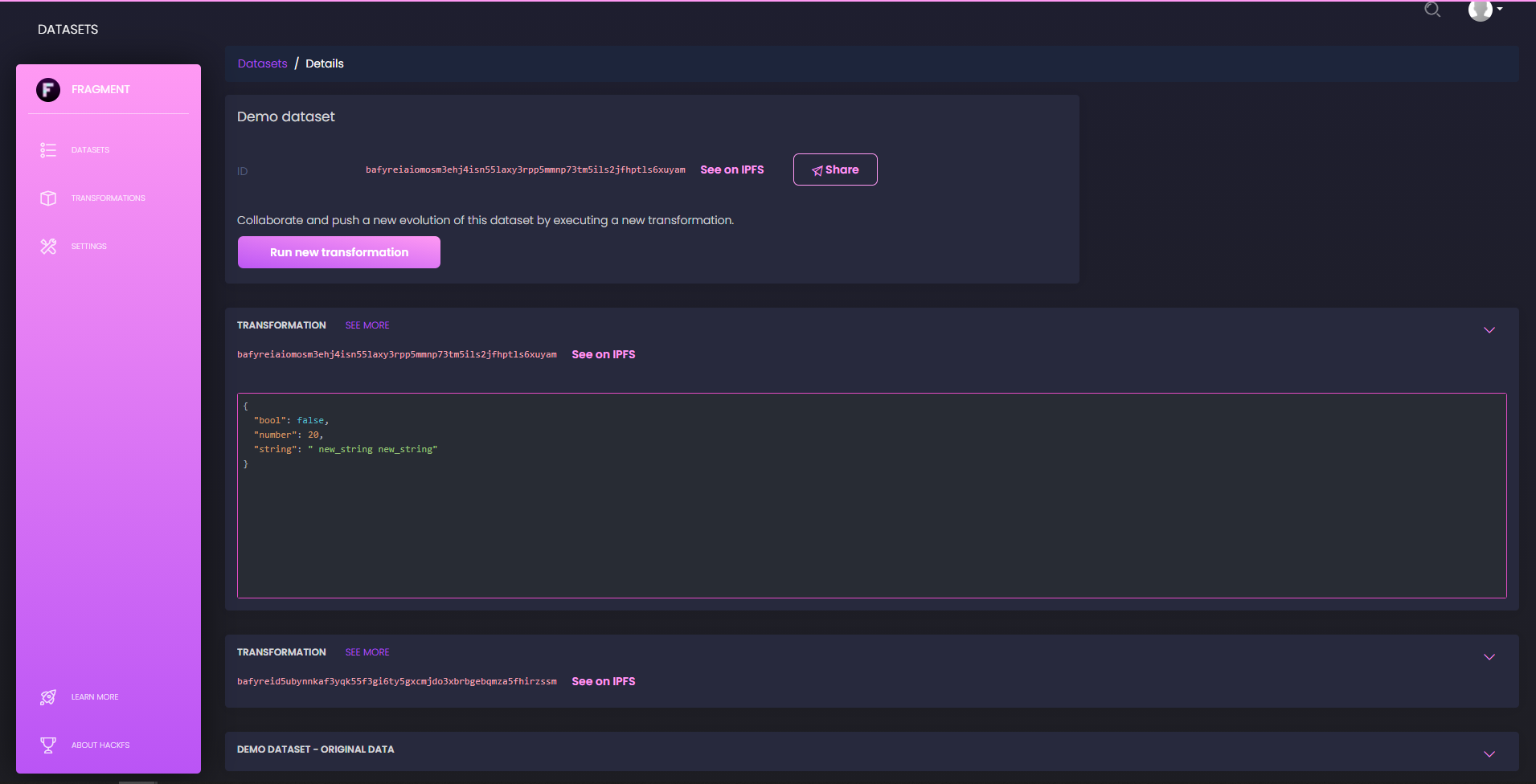
In more details, for this hackathon, we consider any dataset to be a valid JSON document stored on IPFS, and we think of processes as atomic transformations that can be compiled to Wasm bytecode, or at least run inside a Wasm runtime. In this context the theory of data processing is largely simplified and we may think of data pipelines as simple piles of atomic transformations on top of initial datasets. This is precisely what our IPLD schema defines, so that any Fragment object stored on IPFS explicitly contains and/or links to all information related to the history of a given dataset.
This is precisely arranged to also nicely integrate with the Fluence network and its runtime. Processing a dataset, in this framework, simply means contacting a node of the Fluence decentralised network, providing it with the CID of the source data set and the CID of the transformation bytecode, waiting for the execution to succeed and for the result to be pushed on IPFS. We therefore here take advantage of the flexibility of the Wasm runtime, of the decentralisation of the network, and of the ease of integration with IPFS. When the execution of a transformation is over, the new state of the dataset is thus automatically shared on IPFS and anyone can access its full transformation history by following the related IPLD DAG.
On top of this framework, we wanted to build a webapp to first provide an easy-to-use interface leveraging this framework, but also to add a layer of collaboration. For that purpose, we designed an IDX schema and definition that help users publish issues and comments, and precisely attach them to a dataset, at any stage of its transformation history. With flexible timestamped comments, this is a first demonstration of how such schemas could integrate with this pipeline framework, to frame and foster smart collaboration.
We also used more generic schemas to retrieve basic profile information and, for instance, fetch the user's avatar this way.
Last but not least, we showed how web3.storage SDK could be used to easily and safely store initial data sets and transformations' bytecode.

