
Interstellar Thoughts
A protocol and server implementation to allow anyone to host a thought posting server, whose web3-signed contents live on IPFS, and whose users cross-post between servers and migrate between servers at any time.
Project Description
It's become normal for social interaction to happen on a platform that's owned by a giant company, with millions, or even billions of users.
In web2, it's too difficult, expensive, and risky for people to run their own servers.
How can we get back to a future where interoperable social servers are run by individuals and small groups?
The Interstellar concept uses web3, IPFS, and FileCoin to create a protocol for servers to host the thoughts of social groups, small or large, with minimal expense to server-runners, and freedom of cross-server interaction and migration for users, for ever.
ANYONE can run a server. They can configure it for just friends-and-family, use invitations, or leave it open to the public.
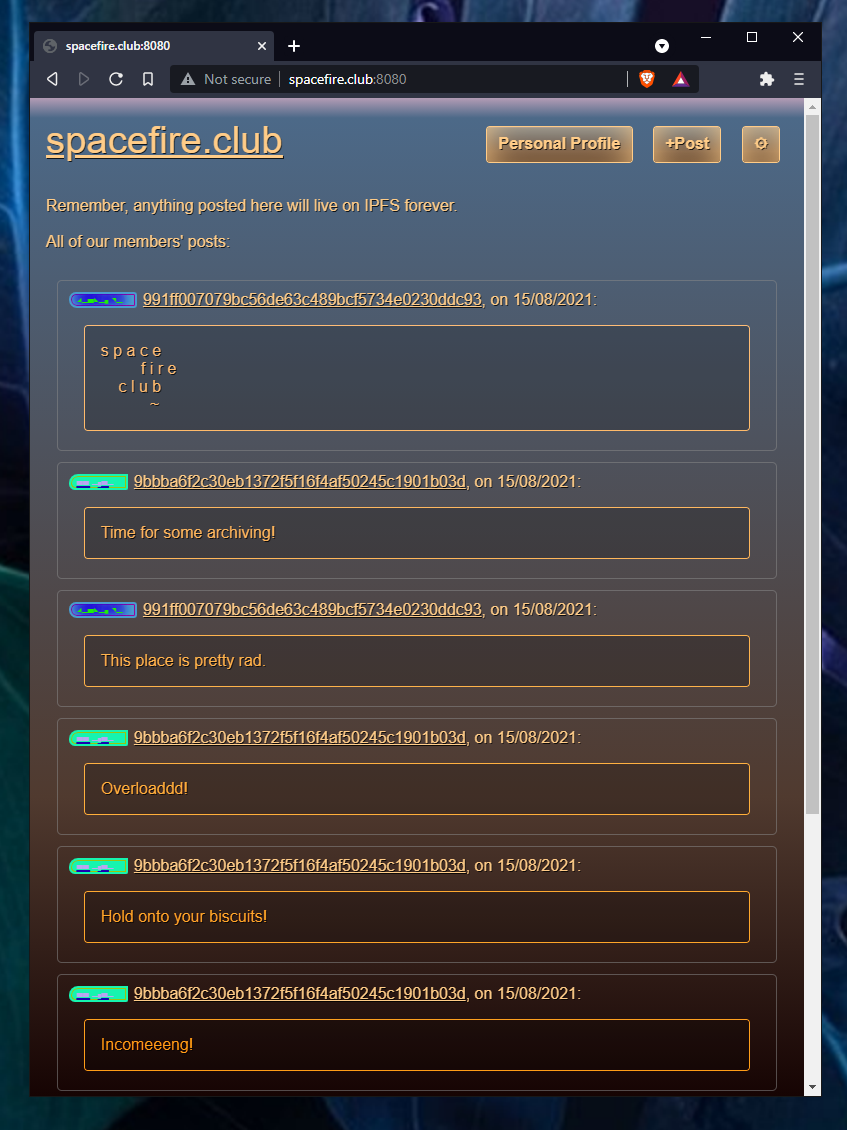
Today we're demoing Interstellar Thoughts - a proof of concept server that anyone can run, which enables Thoughts to be posted by their users, which can be reposted by other users to other servers across the entire network.
Servers receive and verify web3-signed posts from their users, storing recent content locally, then eventually and regularly bundling the archives for storage to IPFS.
If a server goes down or even loses data, routine archival to IPFS means data is easy to recover by either server-runners or even savvy users.
Even in the event of a data breech, no private user-data is ever stored on the server.
This enormously reduces the expense and stress for a server-runner.
Users' content is easy to migrate between servers, and the server-runner doesn't have to feel the need to run it forever.
The Interstellar server protocol lends itself to many types of sub-project, but its first proof of concept is a programme called Interstellar Thoughts.
How it's Made
An Interstellar Thoughts server is an easy-to-run lightweight server. It uses node on the backend, and vanilla JS on the frontend.
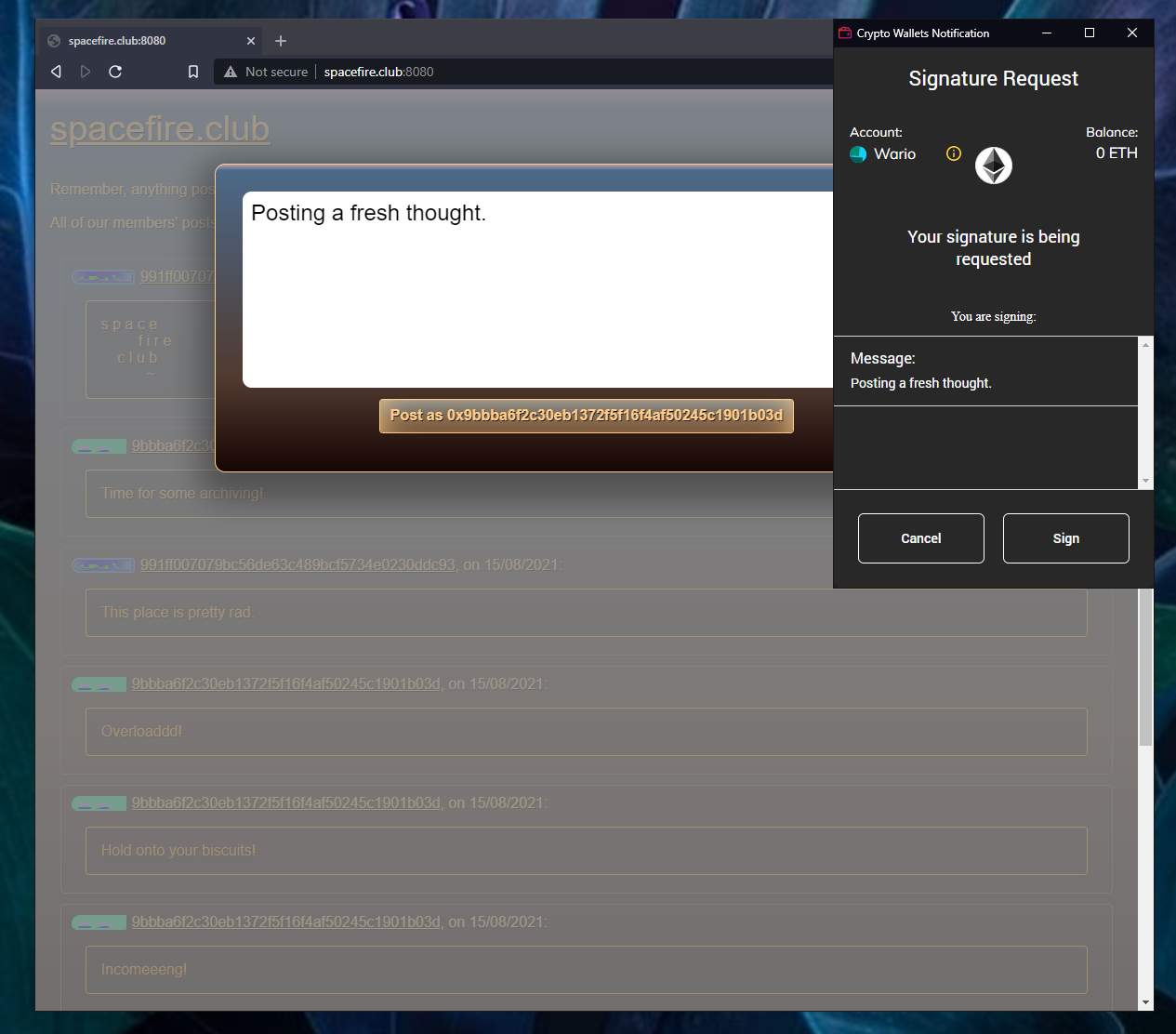
I wanted the code to be as simple as possible. There are very few files to understand on the backend, and the frontend uses no external libraries besides web3. web3.js is loaded through IPFS, so if that’s cached, the payload when visiting any given server will be a few KB, tops.
My favourite features are the archiving and migration. After a certain number of Thoughts are posted by a user (the sever-runner chooses the threshold) then the log of their posts gets added to IPFS via web3.storage. The new CID is stored on the log still living on the server, and the ‘archived’ posts are deleted. This keeps the on-server footprint extremely small. One feature that isn't finished is that the server can allow users to migrate by letting them download this small log to upload to another server. A properly thorough migration would repin ALL migrated content - it has some complexity I'd rather think through after the hackathon's over. :)
An aspect I'm especially pleased about is the in-memory database that saves to the filesystem. All asynchronous writes are batched and tracked, and if the server needs to restart or quit, whether by manual shutdown or auto-restart due to config change, then all batched writes are run immediately before safely shutting down.
This isn't the first time I've used this kind of system, but I wrote it fresh for the hackathon, and I'm very pleased with it how well it's working.
I suspect most people would suggest using a third party database, but I wanted something simple with no moving parts that anyone could run without the risk of extra debugging. It also keeps the storage format extremely flexible, extensible, and portable.
One last thing (I'm not sure this is the right context for it, but..) to disclose parts of the code that were made before the hackathon:
-
The lovely button CSS
-
The auto-generated icons (although it was originally written for UUIDs!)

